

Federated Learning has come a long way since it was formalised by McMahan et al. 2017. Gone are the days when it was reduced to MNIST-level training or equivalent toy examples with small ML models. This blogpost introduces a code example that takes Open AI’s Whisper, a state-of-the-art ASR model, and finetunes it for the downstream task of keyword spotting. You will learn how to perform this downstream in a federated manner. You can find the complete example on GitHub.
Federating Whisper for the downstream task of keyword spotting
Federated Learning can leverage large models trained on publicly available data and downstream them using sensible/private data without having to copy the data to a central server. Flower takes the training to the data source, a critical first step towards ensuring client privacy.
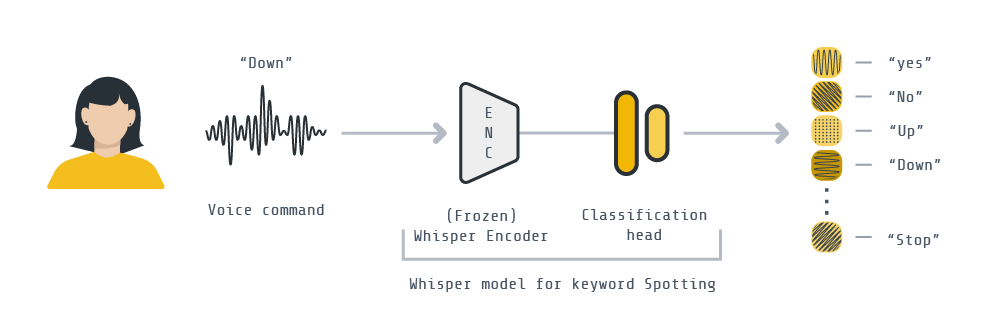
This example walks you through the process of designing a Federated Learning pipeline with Flower for keyword spotting classification. We’ll use a pre-trained Whisper encoder from 🤗 Transformers, freeze its parameters, and federate the learning of a classification head to classify 1-second audio waveforms into one of twelve possible classes: 'yes', 'no', 'up', 'down', 'left', 'right', 'on', 'off', 'stop', 'go', a silence, or an unknown word. For this example, we will use the Google SpeechCommands dataset.
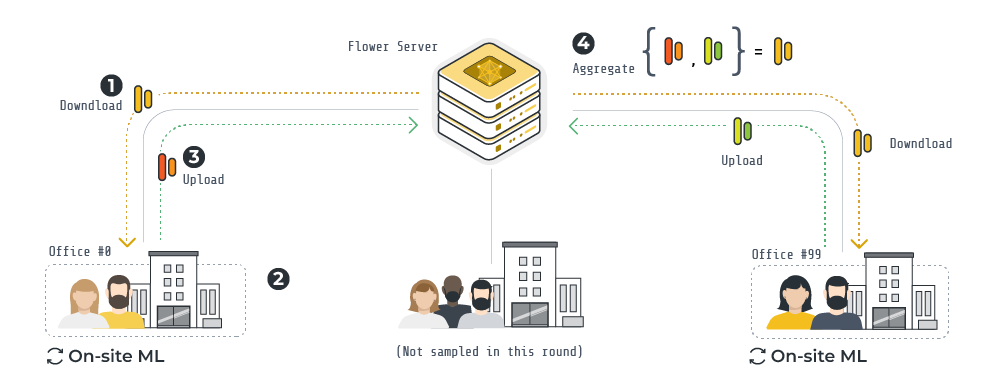
An overview of the FL pipeline implemented with Flower for this example is shown in the diagram above. It has four distinct stages:
- At the beginning of a round, the server samples some clients and sends them the classification head (i.e. the part of the model being federated).
- Each client, with a frozen pre-trained Whisper encoder, trains the classification head using its own data.
- Once on-site training is completed, each client communicates the updated classification head back to the server.
- The server aggregates the classification heads and obtains a new global classification head that will be communicated to clients in the next round.
Running the example
The example available on GitHub splits the 2112 speakers in the SpeechCommands dataset into 100 groups. Each group can be seen as an office with 21 workers. This splitting creates 100 non-iid offices, each having different amounts of training data. We treat each of these offices as a FL client. The FL training uniformly samples 10 clients each round and uses FedAvg for aggregation. Within just a few rounds, the keyword spotting model can classify unseen keywords with an accuracy of over 97%. Recall that only the classification head (which has less than 0.8 M parameters) is being trained.

Running on Raspberry Pi
We used this example to also benchmark the new Raspberry Pi 5. It exhibits vastly superior performance across tasks compared to the previous Raspberry Pi 4, making it suitable for demanding on-device training workloads like the one in this example.
We benchmarked not only training times but also the time taken to pre-process the dataset partitions. A summary of the results are shown below. With a more detailed discussion in code example on GitHub. Times are shown in minutes:seconds.
| Stage | Notes | RPi 4 | RPi 5 |
|---|---|---|---|
| Filter training set (~85k rows) | doing .filter() in client.client_fn | 1:58 | 0:37 |
| Encode 845 rows with WhisperProcessor | doing .map() passing utils.prepare_dataset() | 1:55 | 1:06 |
| On-device training for 1 epoch (925 examples) | finetuning classification head with frozen Whisper encoder | 39:45 | 20:06 |