

Federated Learning (FL) is catching traction and it is now being used in several commercial applications and services. For example, Google uses it for mobile keyboard prediction, while Apple uses FL to improve Siri. In this blog post, I will first give a primer on FL by comparing it against a standard datacenter setup. Then, I'll motivate the use of Federated Learning on embedded devices and, end this blog post by providing a walk-through on how you can set up and run FL applications on embedded devices using Flower.
By the end of this post, you will understand the key difference between distributed and federated learning as well as how to apply federated learning to a real problem.
What is Federated Learning?
We will start by giving a brief overview of what are the unique aspects of Federated Learning (FL) and how it differs from other forms of learning such as datacenter-based distributed learning.
-
Distributed learning: Under this setting clients are compute nodes (e.g. a server with a few GPUs) and the dataset is controller by whoever manages the datacenter, thus it can be shuffled and balanced across clients. All clients are almost always available and typically there are 1-1000 of them. The learning process is centrally orchestrated by another server in the datacenter.
-
Federated learning: By contrast in an FL setting, the clients are independent and often much more constrained compute nodes (e.g your smartphone) that own the data and never send it to the central server. In this way, learning happens locally in each node using their own data and, once the on-device learning stage is completed, the nodes send their updates to the central server, where the results get aggregated. Finally, the central server generates a new global model. The number of clients in FL can reach millions of nodes, but only a fraction of them might be available for a given round of training. The amount and quality of data might vastly differ from client to client. Because clients own the data, FL can offer privacy guarantees that aren't possible in datacenter-based learning approach where privacy is mostly based on a trust agreement.
The diagram bellow illustrates the key differences (left: federated learning, right: classical distributed training in datacenter):
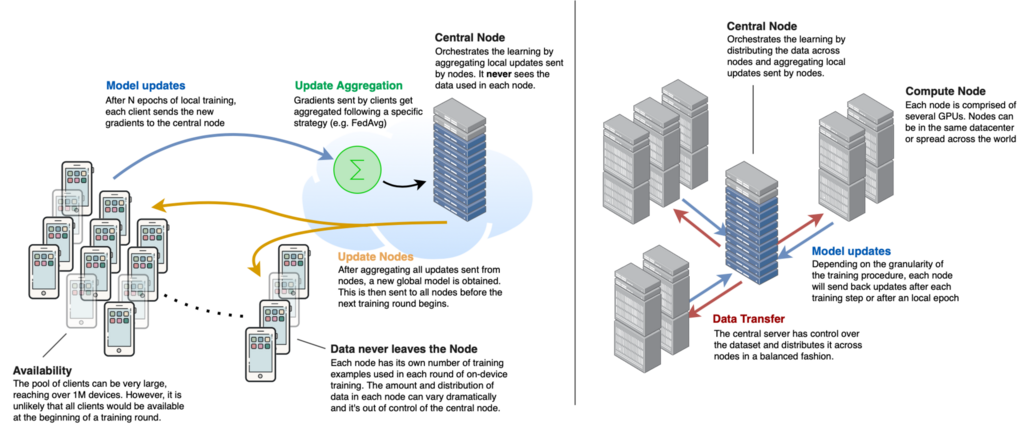
For a more in-depth analysis of different training setups please check Advances and Open Problems in Federated Learning, Kairouz et al. (2019)
Motivating FL on Embedded Devices
Here I present a hypothetical example showing how Federated Learning brings value in privacy sensible contexts such as smart appliances using computer vision. I'll use this example to motivate the use of Federated Learning on embedded devices.
Let's assume there is a company out there that offers a service by which you can easily keep track of what's in your fridge. Such service only requires you to (1) install a small camera with an embedded computer inside your fridge (we'll refer to this device as a "FridgeCam") and (2) connect the device to your WiFi network. Upon installation, the FridgeCam will download a pretrained model from the server offering the service of detecting and classifying the items in your fridge.
However, this initial classification model isn't very good. The main reason being that there are not publicly available datasets that capture the wide variety of items that can be found inside a fridge as well as the different levels of occlusion, viewing angles and, illumination conditions. Because of this, the service provider offers an opt-in program for users to collaborate with the images captured by their FridgeCams and use them to build a better classification model.
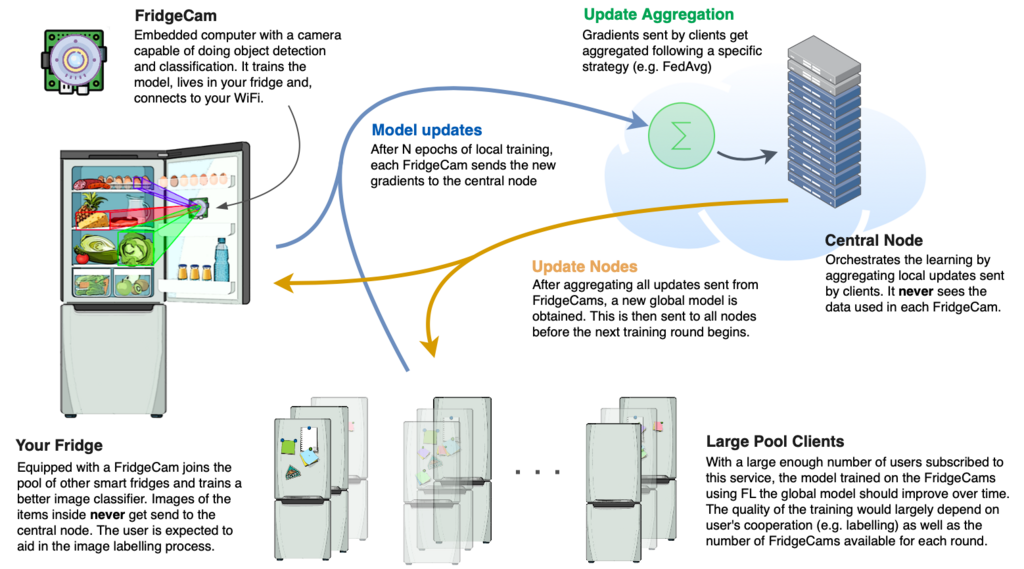
Privacy is an obvious concern here. As a result, many users might not want to share the content of their fridge. For example, some might not want to share images showing alcoholic drinks, others would be worried about sharing some medication that needs to be stored in the fridge. Whatever the reason is, Federated Learning with its privacy guarantees is currently the best way of training a better global model without sharing any data with the service provider.
If a sufficiently large pool of users with their FridgeCams joins the service and, if they are willing to contribute towards the FL learning process (which will also involve some regular image annotation effort from their side), this long-awaited service of keeping track of what's on your fridge could become a reality :relieved:.
Using Flower on Embedded Devices
Using embedded devices as FL clients could be cumbersome as it might require substantial configuration to get the machine learning framework (e.g. PyTorch or Tensorflow) running efficiently on these devices. How can I automate this process as well as setting up the communication with the server?
With Flower you can run FL on embedded devices after a minimal setting up process. We have dockerized the Flower clients to make the process of adding them to the FL pool of clients as seamless as possible. This means that the only requirement to use Flower clients is to install Docker in your embedded device (e.g. a Raspberry Pi). We provide a step-by-step guide on how to do this here. Once Docker is up and running, everything is ready to launch an FL training pipeline that trains on-device an image classification model. The following diagram illustrates the setup for this example.
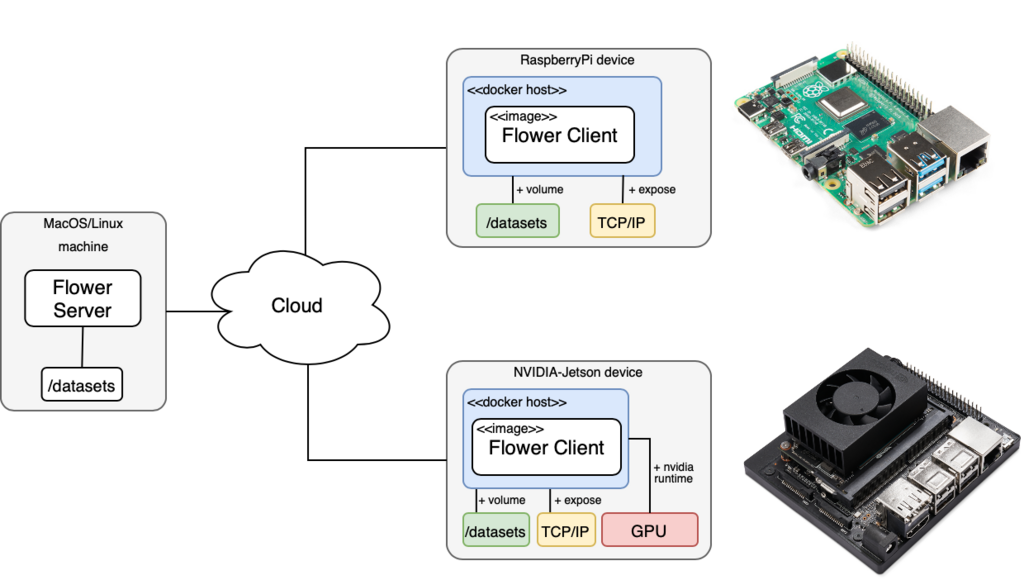
In the example we provide, we present a simpler scenario from what was described in the previous section using FridgeCams. Instead, we will show how to train an image classifier for CIFAR-10 dataset in a Federated Learning fashion. An equivalent setup could be used to make FridgeCams a reality so, if this idea sounds exciting to you, feel free to join our Slack channel to discuss it! In the meantime, you can run our CIFAR-10 example by:
First, launch the server in your machine (i.e. your laptop) by specifying your machine's IP address, the number of FL rounds and, the model to use:
# launch your server. It will be waiting until two clients connect
$ python server.py --server_address <YOUR_SERVER_IP:PORT> --rounds 3 --model NetIf you have just one device around to act as a client you can still run this demo by supplying --min_num_clients=1 and --min_sample_size=1 when you launch the server. Please refer to this example's repository for additional details.
Then, launch the Raspberry Pi client:
# where `cid` is your unique client id, and `model` is the architecture to use
$ ./run_pi.sh --server_address=<SERVER_ADDRESS> --cid=0 --model=NetThen, launch the Jetson client:
# make sure the --cid is unique
$ ./run_jetson.sh --server_address=<SERVER_ADDRESS> --cid=1 --model=NetInternally, run_pi.sh and run_jetson.sh are identical with the exception that the former pulls a Docker image with PyTorch compiled for Arm CPUs and the latter pulls another with GPU support for NVIDIA-Jetson devices. Then, the Dockerfile recipe (see below) downloads the CIFAR-10 dataset. The last stage in the Docker build process copies the two scripts needed to run the Flower Client: client.py and utils.py.
ARG BASE_IMAGE_TYPE=cpu
# these images have been pushed to Dockerhub but you can find
# each Dockerfile used in the `base_images` directory
FROM jafermarq/jetsonfederated_$BASE_IMAGE_TYPE:latest
RUN apt-get install wget -y
# Download and extract CIFAR-10
ENV DATA_DIR=/app/data/cifar-10
RUN mkdir -p $DATA_DIR
WORKDIR $DATA_DIR
RUN wget https://www.cs.toronto.edu/\~kriz/cifar-10-python.tar.gz
RUN tar -zxvf cifar-10-python.tar.gz
WORKDIR /app
# Scripts needed for Flower client
ADD client.py /app
ADD utils.py /app
ENTRYPOINT ["python3","-u","./client.py"]The client will print various messages throughout the process. For this particular example, you should expect to see that a successful connection with the server was established and the duration of each of the three training rounds:
# [Docker build output -- omitted]
DEBUG flower 2020-12-12 11:52:54,264 | connection.py:36 | ChannelConnectivity.IDLE
DEBUG flower 2020-12-12 11:52:54,267 | connection.py:36 | ChannelConnectivity.CONNECTING
INFO flower 2020-12-12 11:52:54,267 | app.py:60 | Opened (insecure) gRPC connection
DEBUG flower 2020-12-12 11:52:54,337 | connection.py:36 | ChannelConnectivity.READY
Client 0: get_parameters
Client 0: fit
Training 1 epoch(s) w/ 781 batches each
Epoch took: 204.97 seconds
Client 0: fit
Training 1 epoch(s) w/ 781 batches each
Epoch took: 202.48 seconds
Client 0: fit
Training 1 epoch(s) w/ 781 batches each
Epoch took: 197.53 seconds
DEBUG flower 2020-12-12 12:03:19,797 | connection.py:68 | Insecure gRPC channel closed
INFO flower 2020-12-12 12:03:19,798 | app.py:71 | Disconnect and shut downAnd that’s how easy it is to deploy and run Federated Learning applications with Flower and PyTorch. If you want to use another image classification model you can do so by editing utils.py. If you want to further customize your FL setup or design it from the grounds up, check our previous blog where we showed how to do FL in less than 20 lines of code using Flower and Tensorflow.